LLM evaluation that considers how models think.
ReasonScape treats LLMs as the Information Processing Systems they are - adressing blind spots of static benchmarks with parametric difficulty, truncation-aware scoring/clustering, and forensic analysis (FFT, compression, hazard). Proven on 10B+ tokens.
We fix the biggest evaluation blind spots
Systemic problems in current LLM evaluation—solved with an information-processing pipeline.
Parametric manifolds
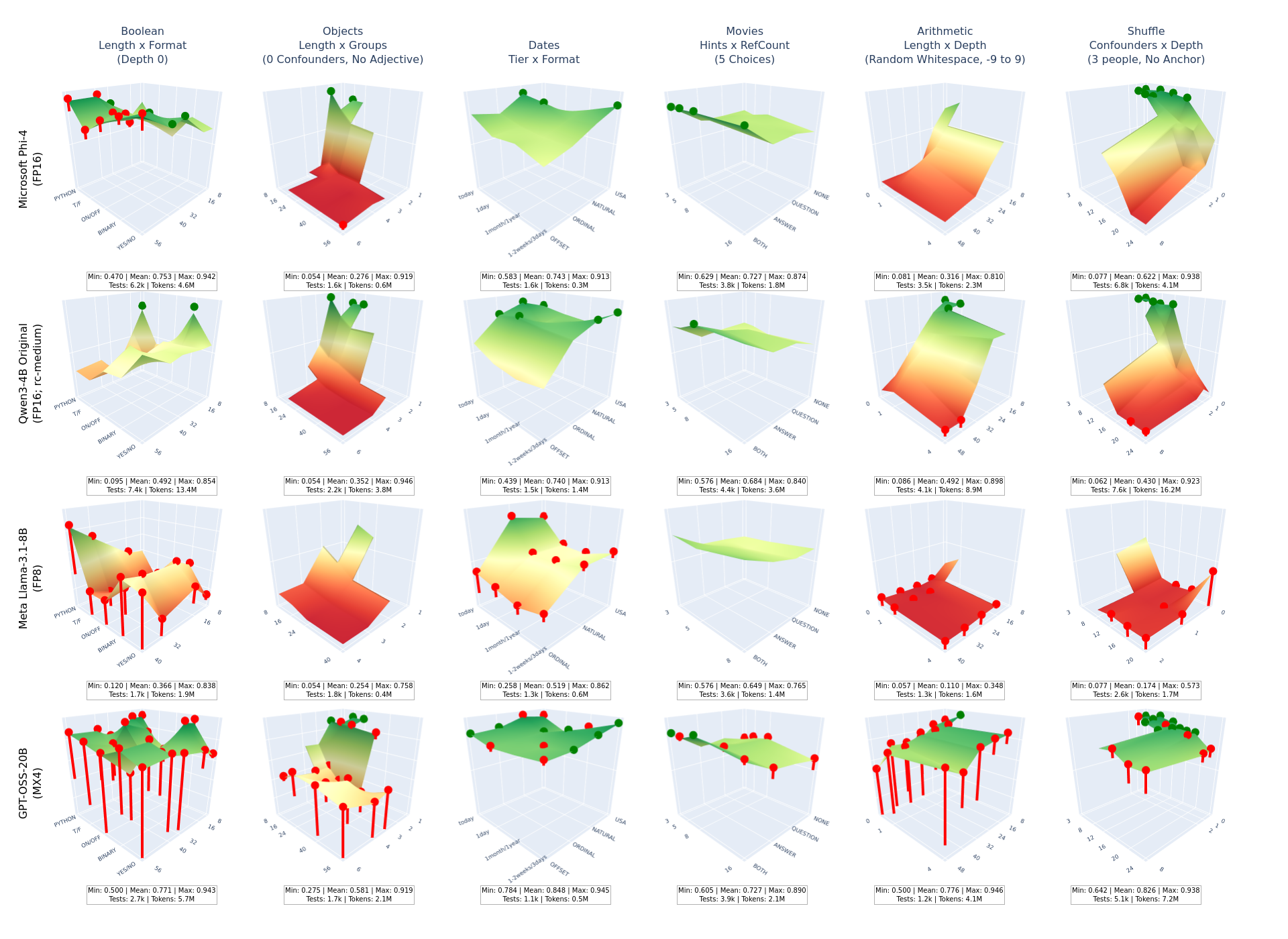
Coordinate-based generation produces infinite, contamination-proof tests with controllable length, depth, interference, and format.
Per-point + confidence
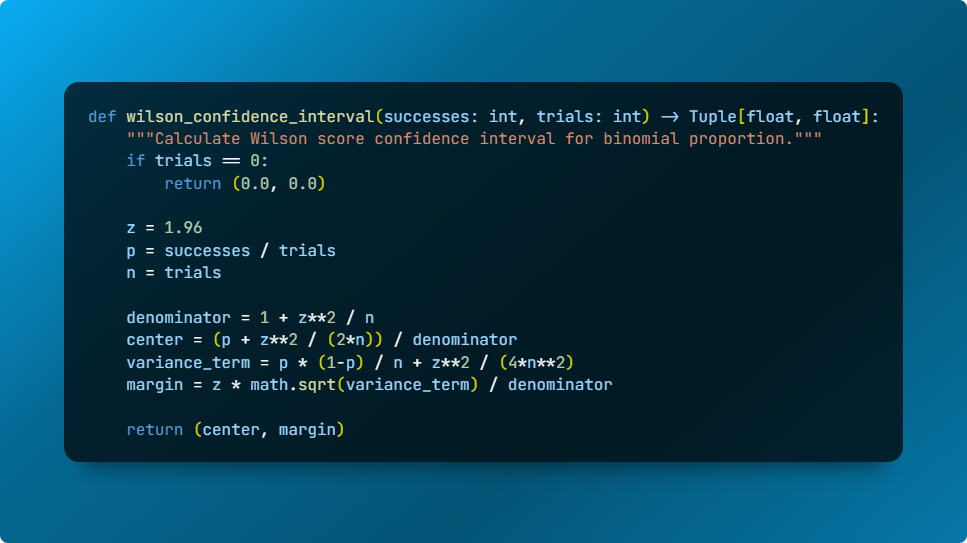
Wilson CIs, excess accuracy, and tiering keep aggregate scores honest and make head-to-head comparisons statistically meaningful.
Forensic signals
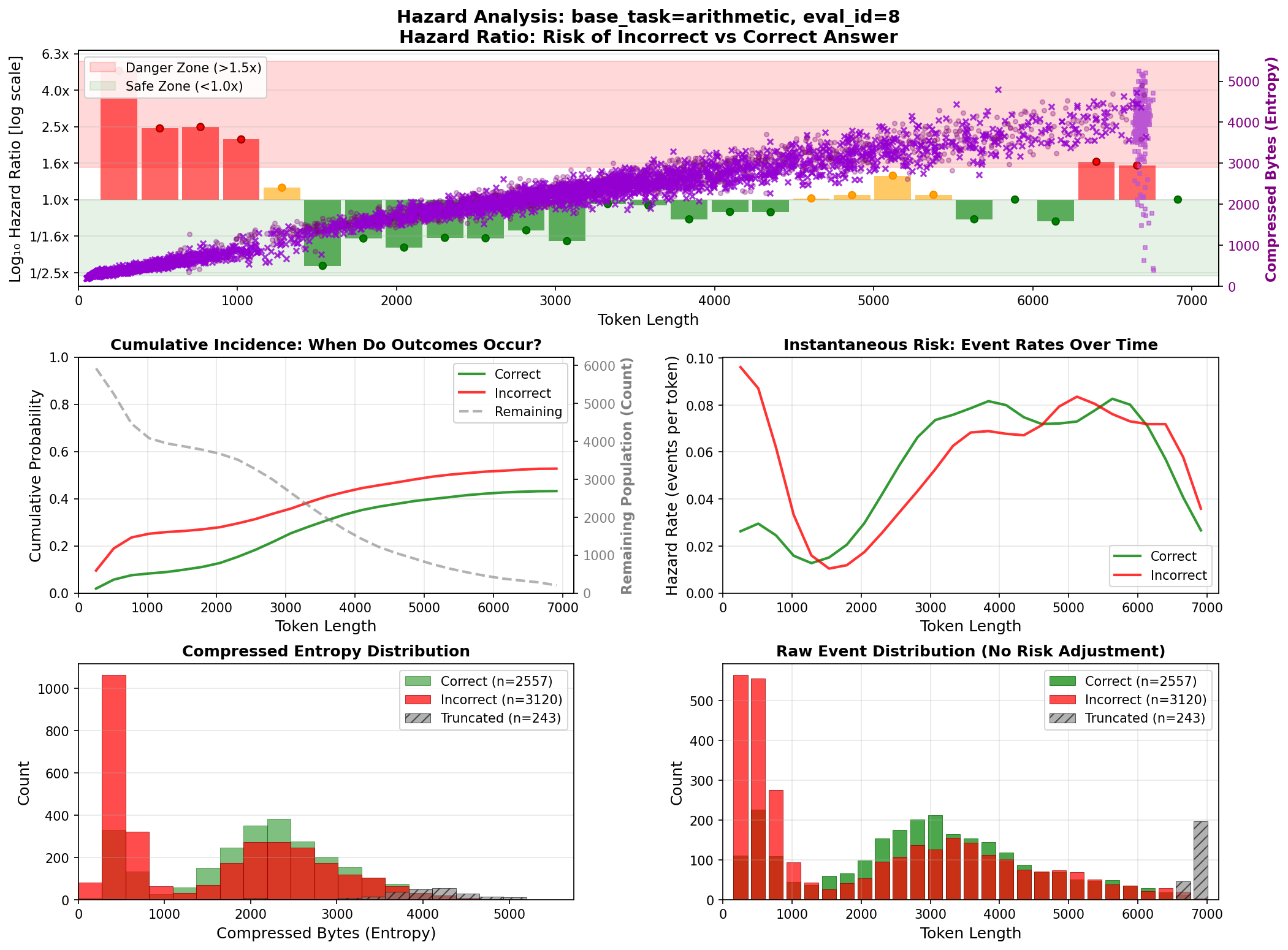
FFT, compression, and hazard analyses expose reasoning quality, loops, and thinking budgets—not just final answers.
Truncation + token cost
Truncations are first-class failures; score/token tracks efficiency so "expensive correctness" stops hiding behind averages.
Live tools you can use now
Explore the data, review the code, compare models, and inspect failure boundaries - all directly from your browser.
Analyze without running inference
The r12 dataset is ready to query. Pull it locally and start exploring reasoning surfaces.
https://github.com/the-crypt-keeper/reasonscape
cd reasonscape
python data.py pull dataset data/r12-leaderboard.json
python analyze.py evals data/r12-leaderboard.json
python explorer.py data/r12-leaderboard.json
Twelve cognitive domains
Breadth of coverage matters. r12 spans across the core reasoning workloads required for practical Reasoning LLM applications. Click on any card below for detailed information!
Multi-step Math
Length × depth manifolds stress symbolic computation with varying whitespace.
Logical evaluation
Nested expressions expose logic consistency, 5 notations tests format sensitivity.
Structural parsing
Stack discipline and pattern tracking, out-of-domain inputs and outputs.
Selective attention
Categorization and counting under load with distractors.
State tracking
Swap sequences test working memory across length and depth with distractors.
Algorithmic thinking
Ordering and language reasoning, output formatting.
Temporal reasoning
Calendar math and pattern recognition, date format variation.
Character analysis
Symbolic parsing with distractors.
Tabular reasoning
Structured data lookup and aggregation under row and column interference.
Rule-based generation
Instruction following with complex constraints.
Spatial reasoning
SVG Shape recognition under rotation, translation and transformation.
Logistics planning
Absolute and Relative spatial operations with interference.
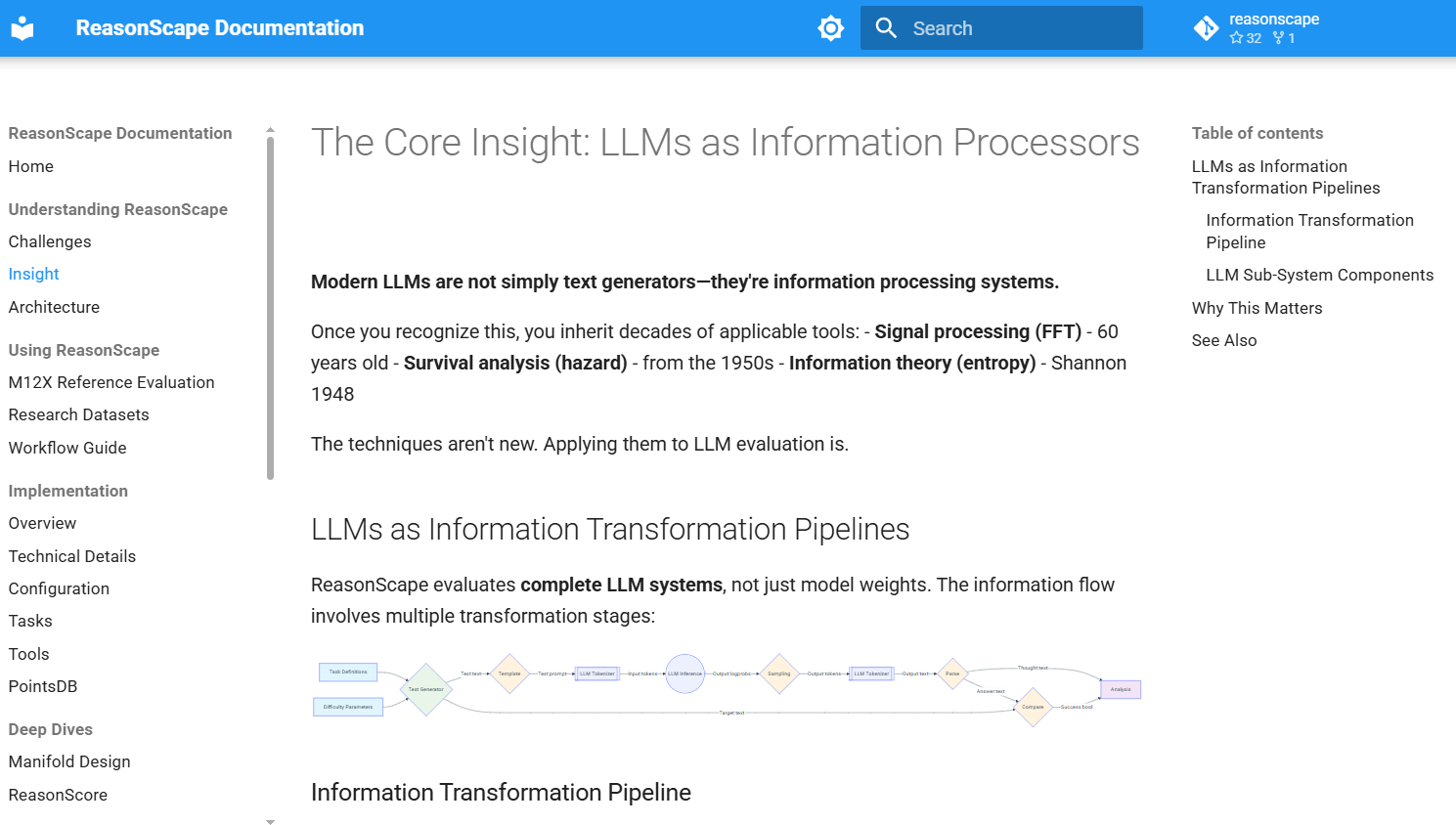
Methodology: Five-stage pipeline
ReasonScape treats LLM evaluation as an information-processing pipeline—from parametric test generation through statistical scoring to forensic root-cause analysis.
Parametric task manifolds; deterministic coordinates.
Adaptive sampling, caching, precision targeting.
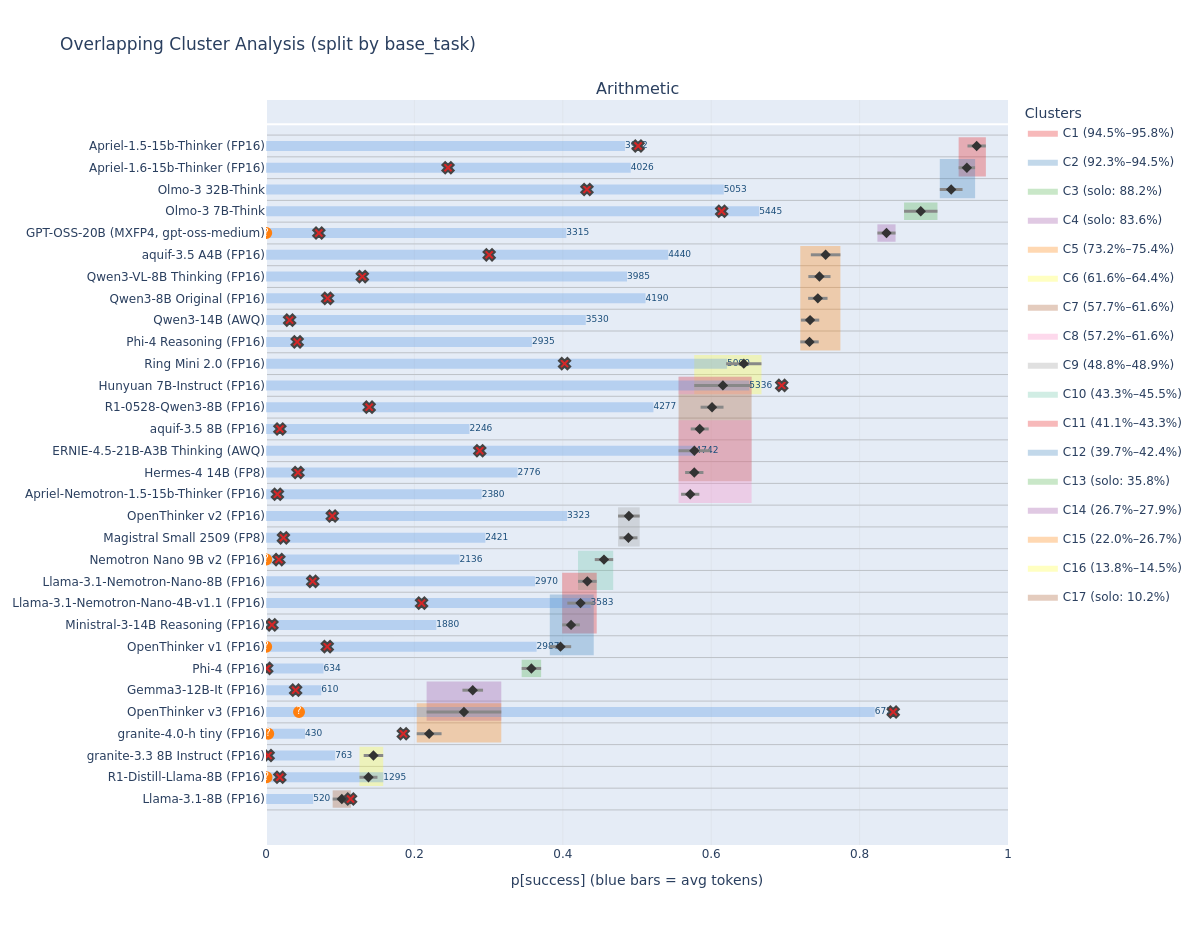
Excess accuracy, truncation penalties, tier mapping.
Leaderboard, spider plots, surfaces for pattern finding.
FFT, compression, hazard to explain root causes.
Analysis Tools
Each tool addresses a specific evaluation question—from aggregate ranking to temporal reasoning behavior forensics.
Unified metric with Wilson CIs, truncation penalties, geometric mean for balance, and score/token efficiency.
Statistical grouping using confidence interval overlap to identify models that are truly indistinguishable.
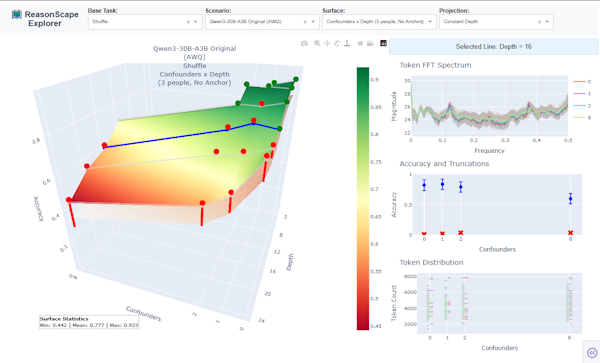
3D visualization of accuracy across parameter grids to identify capability cliffs and performance boundaries.
Frequency domain analysis to distinguish tokenizer effects from model capabilities and output patterns.
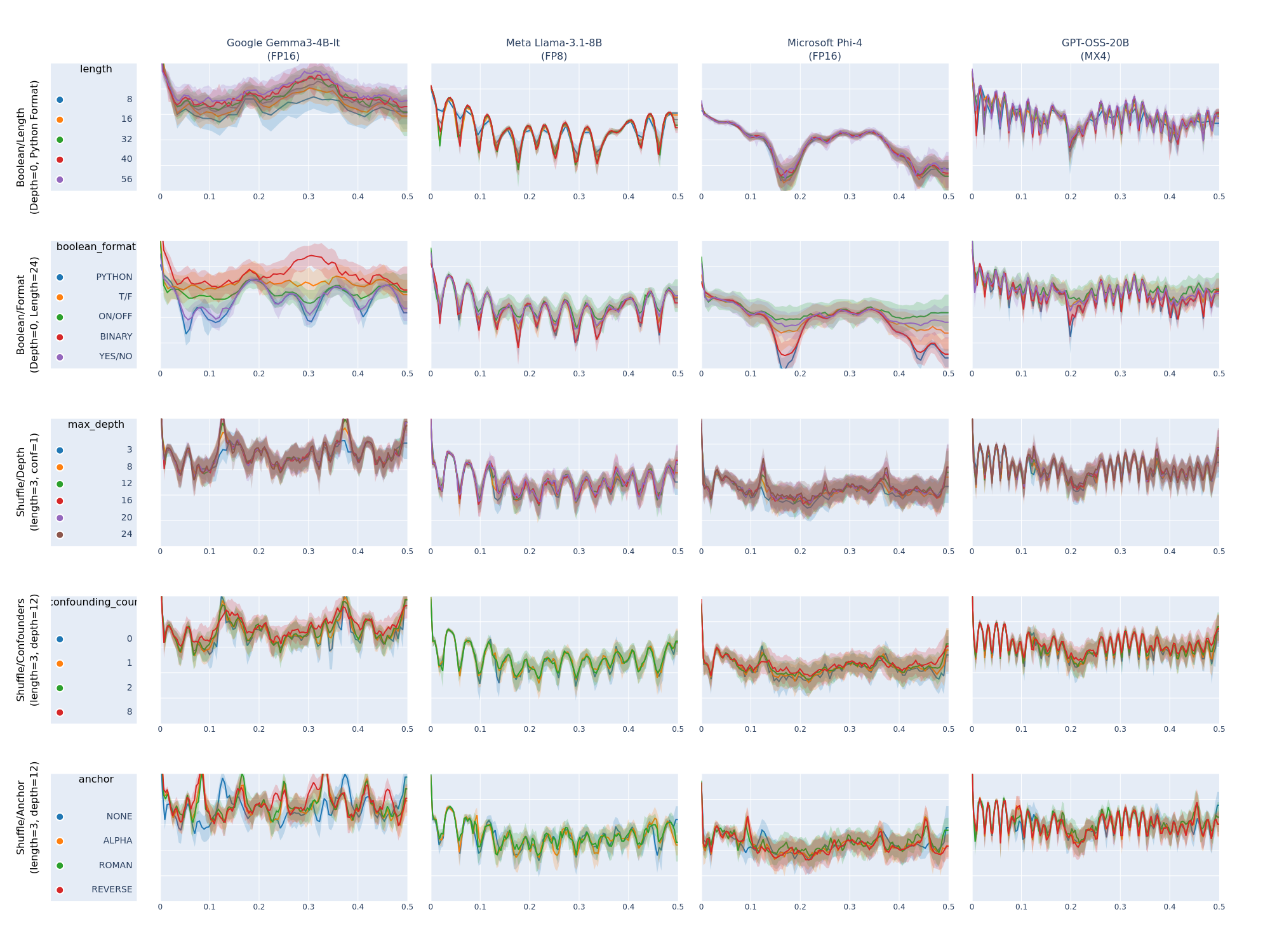
Information-theoretic analysis revealing underthink/overthink patterns and reasoning loop detection.
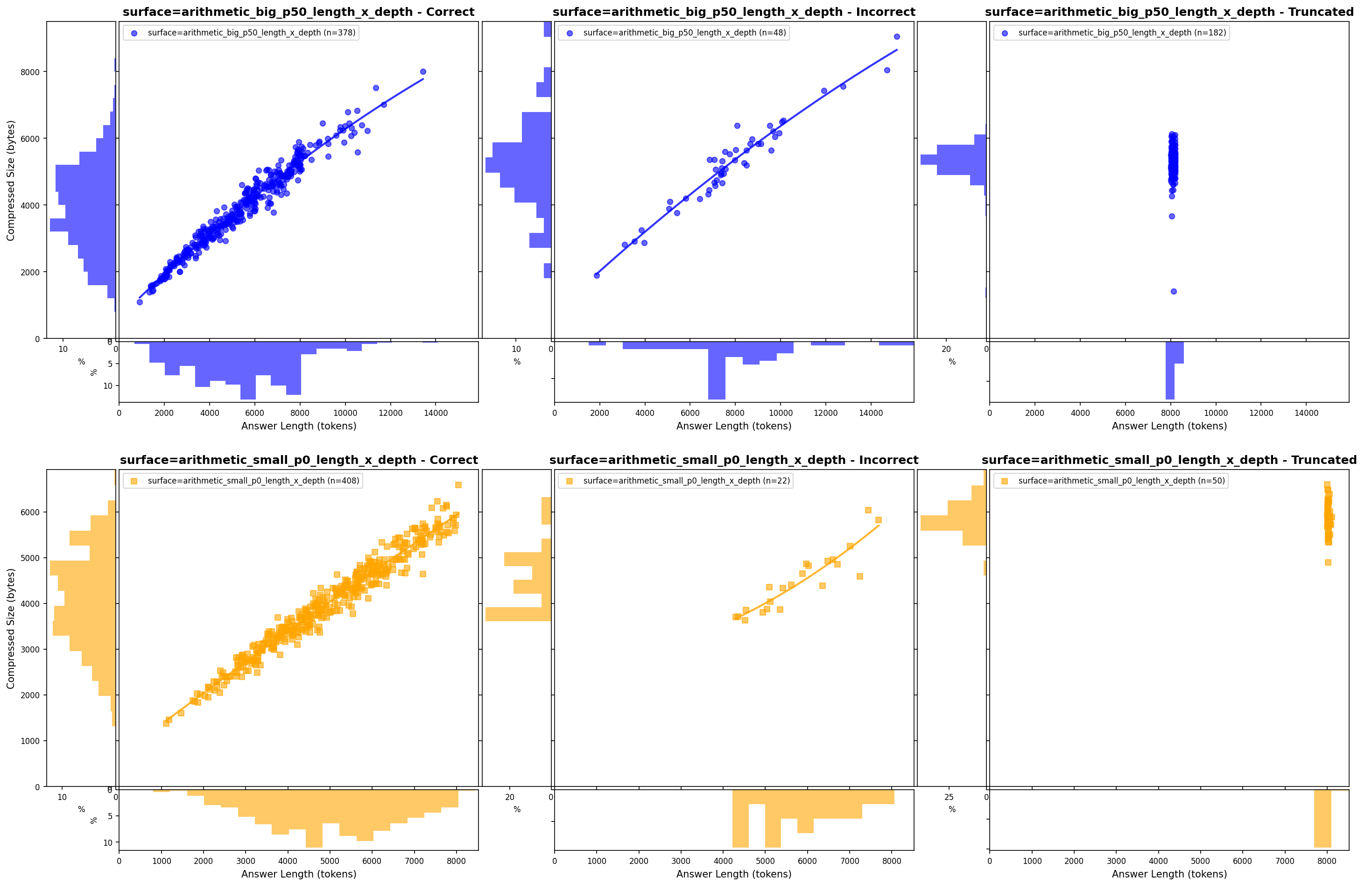
Temporal failure analysis showing when and how models fail during token generation.
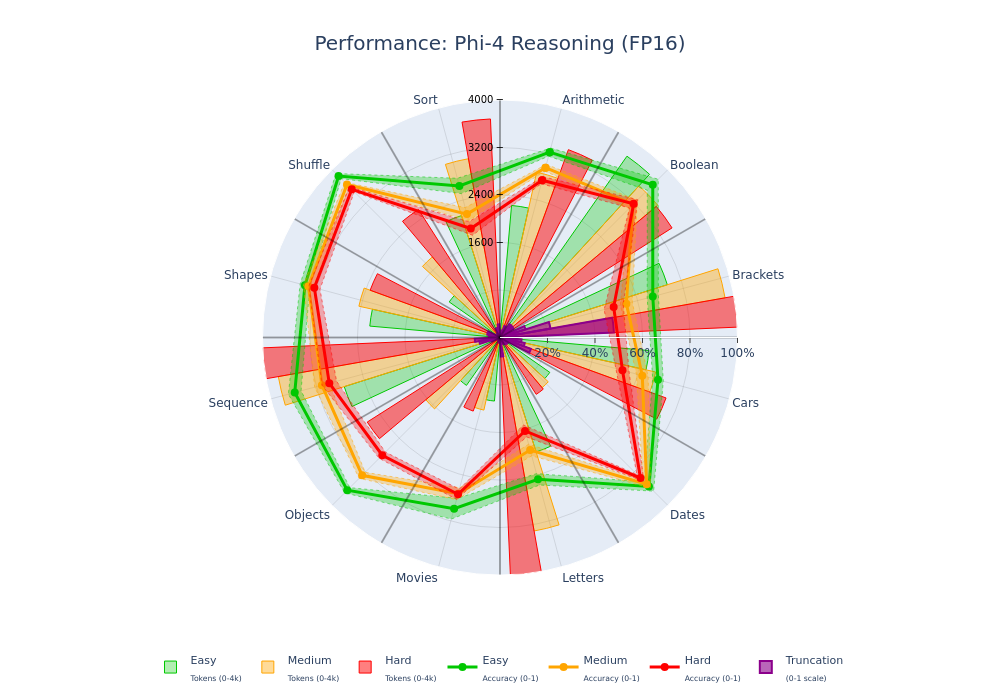
Shows how accuracy and correct/incorrect faceted completion-token distributions change along a difficulty axis.
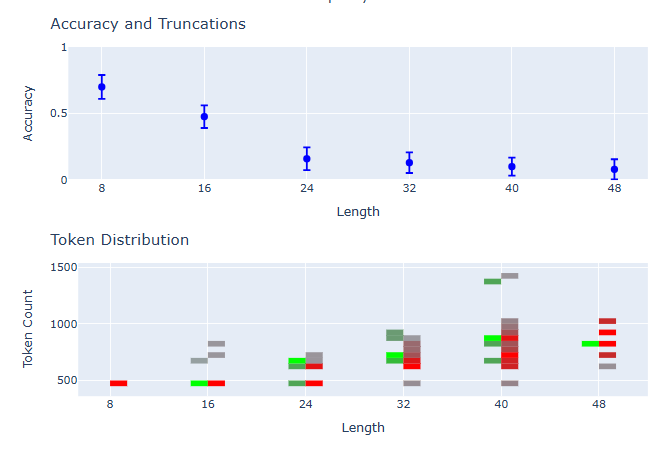
Dual-axis (accuracy, token usage) ignorance region comparison across multiple models and 12 tasks.
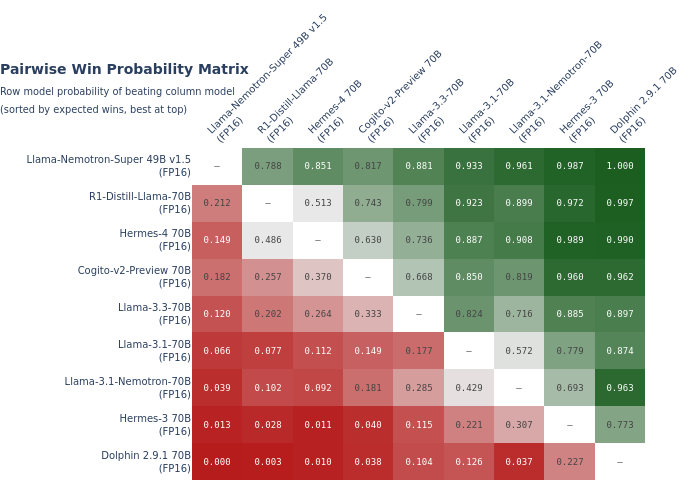
Bradley-Terry cohort comparisons for head-to-head model rankings.
Three research workflows, one unified platform
ReasonScape supports three distinct research activities - each with different tools, questions, and outcomes.
Ranking & Benchmarking
"Which model is better?" — Aggregate rankings to identify 3-5 candidates for deeper investigation.
Model Characterization
"What can this model do?" — Profile cognitive fingerprints, capability zones, and cost/performance characteristics.
Raw Trace Analysis
"How did this fail?" — Examine raw thinking traces with loop detection and classification.